La nostra vita quotidiana è stata notevolmente migliorata dal progresso dell'intelligenza artificiale. Anche il settore agricolo è stato coinvolto da questa nuova tecnologia. Infatti, essa viene utilizzata principalmente per la semina, la coltivazione, il controllo degli insetti, la raccolta e la classificazione dei prodotti post-raccolta.
Il ruolo più importante che si vuole sempre più demandare all’intelligenza artificiale è quello della classificazione e l’elaborazione automatica delle immagini acquisite. I sistemi di selezione automatica della frutta possono essere impiegati per differenziare le diverse varietà di frutta ai fini dell'identificazione e della selezione della frutta durante la raccolta, con l'assistenza di piattaforme robotiche.
Questi sistemi vengono usati anche nel settore del confezionamento, della selezione dei prodotti, nei supermercati, per la definizione dei prezzi per la valutazione della qualità post-raccolta e anche per la fatturazione rapida. È in corso uno sforzo per sostituire i processi manuali di raccolta e selezione della frutta con sistemi automatizzati che impiegano tecniche di visione artificiale e di apprendimento automatico, al fine di migliorare l’efficienza nelle operazioni sia di campo che di post-raccolta.
Le tecnologie informatiche che facilitano la separazione precisa dei frutti sono necessarie negli impianti di lavorazione e confezionamento delle ciliegie. Di conseguenza, le procedure di classificazione sono essenziali per garantire che il prodotto soddisfi gli standard di qualità e che i consumatori ricevano prodotti della qualità desiderata.
Sebbene in letteratura esistano numerosi studi su vari tipi di frutta, non esiste uno studio sperimentale basato su rete neurale convoluzionale sulle specie di ciliegie coltivate in Turchia. Nello studio condotto presso l'Università di Scienze Applicate di Isparta (Turchia), sono stati impiegati metodi di apprendimento insiemistico per ottenere la classificazione delle 7 cultivar di ciliegio utilizzate.
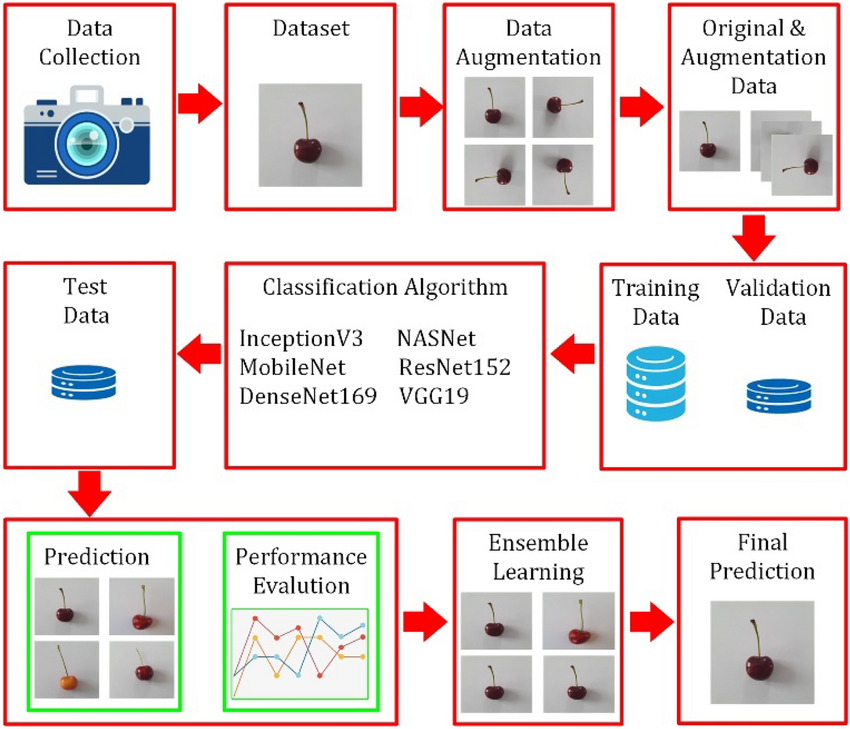
Durante questo studio è stato generato un nuovo set di dati, che comprende 3570 immagini. Utilizzando la tecnica dell'aumento dei dati, i modelli DenseNet169, InceptionV3, MobileNet, NASNet, ResNet152 e VGG19 sono stati addestrati sia sul set di dati originale che su quello incrementale.
Il modello DenseNet169 ha ottenuto le prestazioni di prova più elevate con il 99,57% quando è stato utilizzato il dataset incrementale, mentre il modello InceptionV3 ha ottenuto le prestazioni di prova più basse con il 94,81%. Il modello di apprendimento collettivo Maximum Voting è stato addestrato utilizzando i modelli DenseNet169 e NASNet, che hanno dato i risultati più elevati in termini di accuratezza del test. Il tasso di accuratezza risultante da questo metodo è stato del 100%.
Secondo i risultati ottenuti, il metodo insiemistico proposto come applicazione su ciliegio è più accurato rispetto ai metodi singoli di apprendimento. Nonostante questo sia uno dei primi studi ad occuparsi dell’argomento, il dataset che è stato ottenuto potrà essere impiegato anche nei prossimi studi sul tema.
Tuttavia, il sistema proposto presenta alcuni limiti, ad esempio il ristretto set di cultivar. Inoltre, le variabili ambientali, come l'incapacità di regolare l'illuminazione nell'ambiente controllato, aggravano la sfida di catturare immagini chiare.
I ricercatori si prefiggono l’obiettivo di ampliare ulteriormente il set di dati per includere immagini sia di altre cultivar che di ciliegie provenienti da diverse località del mondo, consentendo la creazione di un modello che riesca a classificare un numero significativamente maggiore di cultivar.
Fonte: Kayaalp, Kıyas. (2024). A deep ensemble learning method for cherry classification. European Food Research and Technology. 250. 1-16. 10.1007/s00217-024-04490-3.
Immagine: Kayaalp
Melissa Venturi
Università di Bologna (IT)
Cherry Times - Tutti i diritti riservati








